Le fichier robots.txt à l'heure des IA
Ce bon vieux fichier robots.txt connaît actuellement un regain d’intérêt afin d’interdire aux robots des IA de se nourrir de vos contenus. Ça m’a motivé pour mettre en ligne un analyseur de fichier robots.txt, lequel n’était jusqu’à présent utilisable que via le crawler. C’est donc la naissance d’un nouvel outil sur Alyze ! L’occasion de revenir sur l’utilité renouvelée du fichier robots.txt face aux intelligences artificielles génératives (IAg ou GenIA pour les intimes).
Quelques rappels sur le fichier robots.txt
Le fichier robots.txt est un incontournable sur le web. Via quelques directives simples, il permet d’autoriser ou non les robots qui parcourent le web à fouiller votre site.
Si vous ne voulez aucun robot sur votre site, rien de plus simple : il suffit de placer dans un fichier robots.txt à la racine de votre site les deux lignes suivantes :
User-agent: *
Disallow: /Les robots sont identifiés via leur user-agent. La première ligne de ce fichier définit donc à qui elle s’adresse. Ici, elle s’adresse à tous les robots. L’astérisque (*) est une wildcard, elle représente n’importe quelle série de caractères. La deuxième ligne commençant par Disallow est assez explicite : elle interdit (disallow) l’exploration à partir de la racine du site. Traduction de ces deux lignes : tous les robots ont l’interdiction d’explorer ce site. Bien entendu, il y aura toujours des robots qui se fichent de ces directives. Il ne faut pas espérer contrôler avec un fichier robots.txt les entités étrangères qui se fichent des règles du web et de la légalité. Dans les autres cas, heureusement majoritaires, le fichier robots.txt reste un moyen efficace d’interdire l’accès à un site.
Hors des cas bien précis (test, préproduction), il n’est généralement pas nécessaire de tout interdire. Il peut cependant être utile d’interdire certaines parties d’un site. Par exemple, pour interdire l’accès à un répertoire perso sur un site, il suffit d’utiliser ce robots.txt :
User-agent: *
Disallow: /perso/On peut aussi jouer avec les directives disallow et allow. Dans notre exemple, pour interdire l’exploration du dossier perso à l’exception du dossier images :
User-agent: *
Disallow: /perso/
Allow: /perso/images/Il est également parfois utile d’interdire l’accès de tout un site à un robot spécifique, particulièrement lorsque ce robot se met à crawler de manière agressive sans raison particulière :
User-agent: MJ12bot
Disallow: /Ici on interdit au robots de Majestic (connu sous l’user-agent MJ12bot) d’explorer tout le site.
Jusqu’en 2023, tout cela semblait bien rodé. Le robots.txt faisait partie des invariants du web depuis des années. Jusqu’à…
L’arrivée des robots IA et de data mining
Début 2023, on a tous été impressionnés par l’IA générative de ChatGPT. Depuis, les IA suscitent un engouement qu’on n’avait pas connu depuis les années 1990 avec l’arrivée de l’internet grand public. Les géants du web investissent des milliards et des startups du monde entier travaillent sur le sujet. Youpi, une nouvelle révolution technologique est en marche !
On s’est toutefois très vite posé la question : où les IA ont-elles appris tout ce qu’elles savent ? Accessoirement, d’où leur viennent leurs opinions (car elles semblent souvent en avoir) ? Il est maintenant clair que la plupart des IA se nourrissent massivement sur le web. Au-delà des problèmes légaux qui ne manquent pas de se poser, les créateurs de contenus peuvent s’émouvoir de servir à abreuver des bases de données gigantesques sans contrepartie. À ce propos, avez-vous essayé de demander à ChatGPT de citer ses sources ?

D’autres IA sont plus transparentes, notamment celles qui peuvent aller chercher « en live » des informations sur le web. Si les sources sont alors citées, elles apparaissent en note de bas de page comme les petites lignes dans les contrats que personne ne lit. On a connu mieux comme récompense pour les créateurs de contenus !
Même si je suis convaincu que les IA génératives sont de formidables outils, je peux comprendre que certains veuillent tout simplement bloquer les robots de ces IA.
La façon la plus propre de parler aux robots IA est d’implanter le protocole TDMRep sur votre site (update : lisez mon article sur le TDMRep !), mais dans l’immédiat le plus simple reste encore d’utiliser ce bon vieux robots.txt pour contrôler les IA.
Contrôler les bots IA avec un fichier robots.txt
Pourquoi je dis que le plus simple est d’utiliser le fichier robots.txt pour contrôler les IA ? Parce qu’il suffit de deux lignes pour interdire à un robot d’explorer un site !
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /Avec ces quatre lignes, vous venez d’interdire votre site à ChatGPT (utilisant l’user-agent GPTBot) et à Google Gemini (utilisant l’user-agent Google-Extended). Vous avez donc, excusez du peu, bloqué les deux principales IA du marché ! Il y en a bien entendu plein d’autres et les choses bougent très vite.
Les grands médias ont déjà compris que leurs productions sont l’or numérique des IA génératives. Interdire ces bots, c’est aussi se ménager la possibilité de négocier financièrement un accès aux contenus, comme le montre l’exemple du journal Le Monde.

Utiliser le testeur de fichiers robots.txt d’Alyze
J’avais codé il y a déjà longtemps un analyseur de fichier robots.txt pour le crawler d’Alyze. Si les robots IA m’ont motivé pour en faire un service indépendant, il est bien entendu pensé pour être avant tout utile pour les usages « classiques » d’un fichier robots.txt.
Pour utiliser ce testeur de robots.txt, il suffit d’entrer l’adresse de la page dont on veut tester l’accessibilité. Le fichier tobots.txt est automatiquement localisé et ses règles extraites.
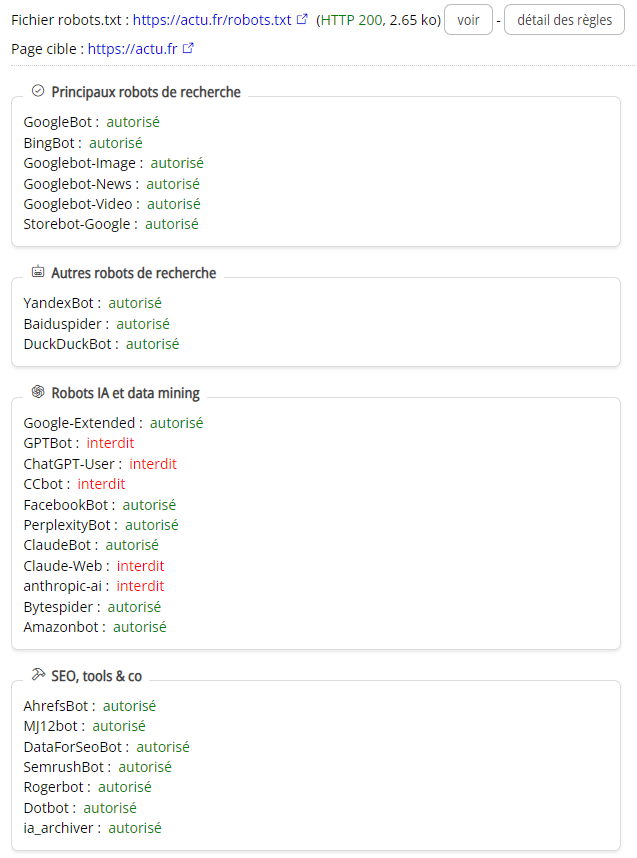
Alyze analyse tout d’abord si les robots classiques, ceux des moteurs de recherches principaux, sont bloqués :
- GoogleBot : le bot de Google
- BingBot : celui de Bing
- Googlebot-Image : utilisé par Google pour nourrir Google images
- Googlebot-News : de même pour Google News
- Googlebot-Video : de même pour Google Vidéos
- Storebot-Google : utilisé par Google pour enrichir ses informations sur des produits (prix, stock, etc.)
Viennent ensuite les robots de recherches moins capitaux sous nos latitudes :
- YandexBot : le bot du moteur de recherche Russe
- Baiduspider : le robot de Baidu, souvent décrit comme le Google chinois
- DuckDuckBot : utilisé par le moteur alternatif DuckDuckGo
Puis les robots d’IA, sachant que la liste est en constante évolution, en voici un aperçu :
- Google-Extended : utilisé par Google Gemini (ex Bard)
- GPTBot : le robot de ChatGPT
- ChatGPT-User : utilisé par les plugins ChatGPT
- CCbot : le bot IA de Common Craw
- FacebookBot : celui de Facebook
- Amazonbot : celui d’Amazon
- PerplexityBot : le bot de l’application Perplexity
- ClaudeBot : le bot d’une des startups les plus avancées avec ChatGPT
- Claude-Web : le Chatbot web de Claude
Il n’y a toutefois pas que les robots des IA et des moteurs de recherche qui parcourent le web, loin de là ! De nombreux outils, certains bien connus des SEO, ont également des bots lancés à la conquête du web :
- AhrefsBot : vous vous demandez comment ahrefs fait pour connaître tous ces liens ? Vous avez la réponse : ils crawlent le web intensément.
- MJ12bot : Majestic fait de même avec ce bot
- SemrushBot : le bot de Semrush
- ia_archiver : c’est à la fois le robot d’exploration d’Alexa et celui qui sert à nourrir archive.org
La liste est bien entendu non exhaustive !
Revenons sur le testeur de robots.txt d’Alyze. Si vous avez plusieurs URL à tester, vous pouvez entrer une URL par ligne dans le formulaire. La présentation sera alors adaptée.

Ce nouvel outil SEO est de plus intégré à l’analyseur de page « classique » d’Alyze. Dans l’onglet Configuration, vous trouverez dorénavant un bouton pour tester le robots.txt du site par rapport à la page analysée. L’analyseur groupé est lui aussi de la partie avec un bouton permettant de vérifier l’accessibilité de l’ensemble des pages analysées en un clic.
